Let’s analyze the reviews for the Fast & Furious 9 movie. If you’re unfamiliar with the premise of the latest outing for Dominic Toretto (played by Vin Diesel) and his family, here’s a brief recap. Following the events of The Fate of the Furious, the crew must face off against Jakob (played by John Cena), who is Dominic’s younger brother and a deadly assassin. Here, we will scrape comments from a Reddit post discusing about their thoughts about the movie.
1. Questions
This analysis will try to answer the following questions:
- What are the Redditors comments on the Fast 9 movie?
- Are the comments mostly potray their opinions or stating a fact?
- What are the positive and negative comments mostly about?
2. Measurement Priorities
- The polarity of the Redditor’s comments by analyzing the sentiment’s polarity score.
- The subjectivity of the Redditor’s comments by analyzing the subjectivity score of the sentiments.
- Creating a collection of words for each polarity of sentiments using word clouds.
3. Data Collection
- Source
- The comments collected will be from reddit.com using their API.
- The python library PRAW will be used to gather the comments.
- Storage
- The collected comments will be stored in a CSV file.
- The cleaned comments will also be stored as both CSV file.
import praw
import pandas as pd
import datetime as dt
Create Instance of Reddit
reddit = praw.Reddit(
user_agent="Comment Extraction (by u/USERNAME)",
client_id="*********",
client_secret="*********",
username="*********",
password="*********",
)
Link to Reddit Post
url = "https://www.reddit.com/r/movies/comments/o7e258/official_discussion_f9_the_fast_saga_spoilers/"
submission = reddit.submission(url=url)
from praw.models import MoreComments
from datetime import datetime
# Create temporary list to hold the comments data.
list_comments=[]
list_time=[]
# Store in a dictionary.
dict_collect = {'comments':list_comments,
'time': list_time,
}
# Loop through each top level comment.
for top_level_comment in submission.comments:
if isinstance(top_level_comment, MoreComments):
continue
# Append comment to list
list_comments.append(top_level_comment.body)
# Convert and append time to list
time = (datetime.utcfromtimestamp(top_level_comment.created_utc).strftime('%Y-%m-%d %H:%M:%S'))
list_time.append(time)
Convert to DataFrame
df = pd.DataFrame.from_dict(dict_collect)
df
|
comments |
time |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
| ... |
... |
... |
| 95 |
F10&11 are gonna get the Infinity War/Endgame ... |
2021-06-26 10:42:18 |
| 96 |
I got many problems with the plot. Doms brothe... |
2021-07-04 20:50:01 |
| 97 |
They did my dude Sean the Tokyo Drifter dirty.... |
2021-07-29 21:03:51 |
| 98 |
I have a nephew who is eight and loves cars bu... |
2021-07-16 06:26:07 |
| 99 |
That Toretto Nordic blood |
2021-06-26 04:02:12 |
100 rows × 2 columns
df.to_csv('dataset/fast_9_review.csv',index = False)
EDA
Let’s take a look at our gathered comments about Fast 9 from the posts.
Word count
eda = pd.read_csv('dataset/fast_9_review.csv')
|
comments |
time |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
eda['word_count'] = eda['comments'].apply(lambda x: len(str(x).split(" ")))
|
comments |
time |
word_count |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
22 |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
22 |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
14 |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
19 |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
28 |
print('Average Word count: '+str(int(eda['word_count'].mean()))+ ' words')
Average Word count: 46 words
Average word lenght
def avg_word(comments):
words = comments.split()
return int((sum(len(word) for word in words) / len(words)))
# Calculate average words
eda['avg_word_len'] = eda['comments'].apply(lambda x: avg_word(x))
|
comments |
time |
word_count |
avg_word_len |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
22 |
4 |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
22 |
4 |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
14 |
4 |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
19 |
3 |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
28 |
3 |
Character count
eda['char_count'] = eda['comments'].str.len()
|
comments |
time |
word_count |
avg_word_len |
char_count |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
22 |
4 |
111 |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
22 |
4 |
126 |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
14 |
4 |
81 |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
19 |
3 |
98 |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
28 |
3 |
135 |
print('Average character count: '+str(int(eda['char_count'].mean()))+ ' words')
Average character count: 251 words
Stopword count
# Import stopwords
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
eda['stopword_count'] = eda['comments'].apply(lambda x: len([x for x in x.split() if x in stop_words]))
|
comments |
time |
word_count |
avg_word_len |
char_count |
stopword_count |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
22 |
4 |
111 |
9 |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
22 |
4 |
126 |
8 |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
14 |
4 |
81 |
5 |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
19 |
3 |
98 |
7 |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
28 |
3 |
135 |
12 |
Summary statistics
|
word_count |
avg_word_len |
char_count |
stopword_count |
| count |
100.000000 |
100.000000 |
100.000000 |
100.000000 |
| mean |
46.480000 |
4.040000 |
251.420000 |
18.430000 |
| std |
64.721233 |
1.033969 |
355.543465 |
26.918228 |
| min |
1.000000 |
3.000000 |
9.000000 |
0.000000 |
| 25% |
14.000000 |
4.000000 |
67.000000 |
5.000000 |
| 50% |
22.500000 |
4.000000 |
126.000000 |
9.000000 |
| 75% |
51.250000 |
4.000000 |
268.750000 |
21.250000 |
| max |
465.000000 |
9.000000 |
2604.000000 |
196.000000 |
Process Text
data = pd.read_csv('dataset/fast_9_review.csv')
|
comments |
time |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
Convert to lowercase
# Converting each comments to lowercase
data['lowercased'] = data['comments'].apply(lambda x: " ".join(x.lower() for x in x.split()))
|
comments |
time |
lowercased |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
if you’re ever falling to your death try land ... |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
hellen mirren saying john cena and vin diesel ... |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
i think the most intimidating villain in the m... |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
tez: we'll be alright as long as we obey the l... |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
i wish dom would interact more with the rest o... |
Punctuations removal
# remove punctuations from comments
data['nopunc'] = data['lowercased'].str.replace('[^\w\s]', '')
<ipython-input-138-94766295ce28>:2: FutureWarning: The default value of regex will change from True to False in a future version.
data['nopunc'] = data['lowercased'].str.replace('[^\w\s]', '')
|
comments |
time |
lowercased |
nopunc |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
if you’re ever falling to your death try land ... |
if youre ever falling to your death try land o... |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
hellen mirren saying john cena and vin diesel ... |
hellen mirren saying john cena and vin diesel ... |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
i think the most intimidating villain in the m... |
i think the most intimidating villain in the m... |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
tez: we'll be alright as long as we obey the l... |
tez well be alright as long as we obey the law... |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
i wish dom would interact more with the rest o... |
i wish dom would interact more with the rest o... |
Remove stopwords
# Import stopwords
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
data['nopunc_nostop'] = data['nopunc'].apply(lambda x: " ".join(x for x in x.split() if x not in stop_words))
|
comments |
time |
lowercased |
nopunc |
nopunc_nostop |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
if you’re ever falling to your death try land ... |
if youre ever falling to your death try land o... |
youre ever falling death try land car break fa... |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
hellen mirren saying john cena and vin diesel ... |
hellen mirren saying john cena and vin diesel ... |
hellen mirren saying john cena vin diesel simi... |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
i think the most intimidating villain in the m... |
i think the most intimidating villain in the m... |
think intimidating villain movie charlize ther... |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
tez: we'll be alright as long as we obey the l... |
tez well be alright as long as we obey the law... |
tez well alright long obey laws physics entire... |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
i wish dom would interact more with the rest o... |
i wish dom would interact more with the rest o... |
wish dom would interact rest crew felt like ha... |
# View the top 30 words used
freq= pd.Series(" ".join(data['nopunc_nostop']).split()).value_counts()[:30]
freq
movie 44
dom 38
like 25
one 19
scene 18
car 17
space 15
also 15
fast 14
family 13
got 13
movies 13
dont 12
end 12
going 12
han 12
felt 11
vin 11
cena 11
doms 11
part 11
back 11
get 10
time 10
even 10
shaw 10
still 10
franchise 9
roman 9
actually 9
dtype: int64
other_stopwords = ['actually', 'time', 'one', 'get', 'got', 'even', 'time']
data['nopunc_nostop_nocommon'] = data['nopunc_nostop'].apply(lambda x: "".join(" ".join(x for x in x.split() if x not in other_stopwords)))
|
comments |
time |
lowercased |
nopunc |
nopunc_nostop |
nopunc_nostop_nocommon |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
if you’re ever falling to your death try land ... |
if youre ever falling to your death try land o... |
youre ever falling death try land car break fa... |
youre ever falling death try land car break fa... |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
hellen mirren saying john cena and vin diesel ... |
hellen mirren saying john cena and vin diesel ... |
hellen mirren saying john cena vin diesel simi... |
hellen mirren saying john cena vin diesel simi... |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
i think the most intimidating villain in the m... |
i think the most intimidating villain in the m... |
think intimidating villain movie charlize ther... |
think intimidating villain movie charlize ther... |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
tez: we'll be alright as long as we obey the l... |
tez well be alright as long as we obey the law... |
tez well alright long obey laws physics entire... |
tez well alright long obey laws physics entire... |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
i wish dom would interact more with the rest o... |
i wish dom would interact more with the rest o... |
wish dom would interact rest crew felt like ha... |
wish dom would interact rest crew felt like ha... |
# Import textblob
from textblob import Word
# Lemmatize final review format
data['cleaned_comments'] = data['nopunc_nostop_nocommon'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
|
comments |
time |
lowercased |
nopunc |
nopunc_nostop |
nopunc_nostop_nocommon |
cleaned_comments |
| 0 |
If you’re ever falling to your death try land ... |
2021-06-25 02:24:48 |
if you’re ever falling to your death try land ... |
if youre ever falling to your death try land o... |
youre ever falling death try land car break fa... |
youre ever falling death try land car break fa... |
youre ever falling death try land car break fa... |
| 1 |
Hellen Mirren saying John Cena and Vin Diesel ... |
2021-06-25 06:23:22 |
hellen mirren saying john cena and vin diesel ... |
hellen mirren saying john cena and vin diesel ... |
hellen mirren saying john cena vin diesel simi... |
hellen mirren saying john cena vin diesel simi... |
hellen mirren saying john cena vin diesel simi... |
| 2 |
I think the most intimidating villain in the m... |
2021-06-25 04:46:46 |
i think the most intimidating villain in the m... |
i think the most intimidating villain in the m... |
think intimidating villain movie charlize ther... |
think intimidating villain movie charlize ther... |
think intimidating villain movie charlize ther... |
| 3 |
Tez: we'll be alright as long as we obey the l... |
2021-06-25 02:46:44 |
tez: we'll be alright as long as we obey the l... |
tez well be alright as long as we obey the law... |
tez well alright long obey laws physics entire... |
tez well alright long obey laws physics entire... |
tez well alright long obey law physic entire m... |
| 4 |
I wish Dom would interact more with the rest o... |
2021-06-25 02:29:29 |
i wish dom would interact more with the rest o... |
i wish dom would interact more with the rest o... |
wish dom would interact rest crew felt like ha... |
wish dom would interact rest crew felt like ha... |
wish dom would interact rest crew felt like ha... |
data[['cleaned_comments','time']].to_csv('dataset/fast_9_review_cleaned.csv',index = False)
Visualization
df = pd.read_csv('dataset/fast_9_review_cleaned.csv')
|
cleaned_comments |
time |
| 0 |
youre ever falling death try land car break fa... |
2021-06-25 02:24:48 |
| 1 |
hellen mirren saying john cena vin diesel simi... |
2021-06-25 06:23:22 |
| 2 |
think intimidating villain movie charlize ther... |
2021-06-25 04:46:46 |
| 3 |
tez well alright long obey law physic entire m... |
2021-06-25 02:46:44 |
| 4 |
wish dom would interact rest crew felt like ha... |
2021-06-25 02:29:29 |
| ... |
... |
... |
| 95 |
f1011 gonna infinity warendgame treatment gonn... |
2021-06-26 10:42:18 |
| 96 |
many problem plot doms brother big spyevil guy... |
2021-07-04 20:50:01 |
| 97 |
dude sean tokyo drifter dirty fuck behind plan... |
2021-07-29 21:03:51 |
| 98 |
nephew eight love car mum wont let watch ff mo... |
2021-07-16 06:26:07 |
| 99 |
toretto nordic blood |
2021-06-26 04:02:12 |
100 rows × 2 columns
Polarity and Subjectivity
Calculate score
# Calculate polarity
from textblob import TextBlob
df['polarity'] = df['cleaned_comments'].apply(lambda x: TextBlob(x).sentiment[0])
# Calculate subjectivity
df['subjectivity'] = df['cleaned_comments'].apply(lambda x: TextBlob(x).sentiment[1])
|
cleaned_comments |
time |
polarity |
subjectivity |
| 0 |
youre ever falling death try land car break fa... |
2021-06-25 02:24:48 |
0.025000 |
0.175000 |
| 1 |
hellen mirren saying john cena vin diesel simi... |
2021-06-25 06:23:22 |
0.066667 |
0.266667 |
| 2 |
think intimidating villain movie charlize ther... |
2021-06-25 04:46:46 |
0.000000 |
0.000000 |
| 3 |
tez well alright long obey law physic entire m... |
2021-06-25 02:46:44 |
0.087500 |
0.581250 |
| 4 |
wish dom would interact rest crew felt like ha... |
2021-06-25 02:29:29 |
-0.291667 |
0.541667 |
# Summary statictics of the scores
df.describe()
|
polarity |
subjectivity |
| count |
100.000000 |
100.000000 |
| mean |
0.057331 |
0.439929 |
| std |
0.286197 |
0.272889 |
| min |
-0.900000 |
0.000000 |
| 25% |
0.000000 |
0.300000 |
| 50% |
0.046165 |
0.435020 |
| 75% |
0.200000 |
0.606399 |
| max |
1.000000 |
1.000000 |
Label the scores
# Add polarity label
def polar_label(polar):
if (polar<-0.5):
return "negative"
elif (polar>=-0.5) and (polar<0):
return "weak negative"
elif (polar==0):
return "neutral"
elif (polar>0)and(polar<=0.5):
return "weak positive"
else:
return "positive"
df['polar_label'] = df['polarity'].apply(lambda x: polar_label(x))
# Add subjectivity label
def subj_label(subj):
if subj<0.5:
return "objective"
elif subj==0.5:
return "neutral"
else:
return "subjective"
df['subj_label'] = df['subjectivity'].apply(lambda x: subj_label(x))
|
cleaned_comments |
time |
polarity |
subjectivity |
polar_label |
subj_label |
| 0 |
youre ever falling death try land car break fa... |
2021-06-25 02:24:48 |
0.025000 |
0.175000 |
weak positive |
objective |
| 1 |
hellen mirren saying john cena vin diesel simi... |
2021-06-25 06:23:22 |
0.066667 |
0.266667 |
weak positive |
objective |
| 2 |
think intimidating villain movie charlize ther... |
2021-06-25 04:46:46 |
0.000000 |
0.000000 |
neutral |
objective |
| 3 |
tez well alright long obey law physic entire m... |
2021-06-25 02:46:44 |
0.087500 |
0.581250 |
weak positive |
subjective |
| 4 |
wish dom would interact rest crew felt like ha... |
2021-06-25 02:29:29 |
-0.291667 |
0.541667 |
weak negative |
subjective |
# count of polar label
df['polar_label'].value_counts()
weak positive 52
neutral 20
weak negative 19
positive 5
negative 4
Name: polar_label, dtype: int64
Score distribution
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5),facecolor='1')
plt.title('Polarity score distribution')
sns.kdeplot(
data=df, x="polarity",
fill=True, palette="Set1",
alpha=.5, linewidth=1)
plt.show()
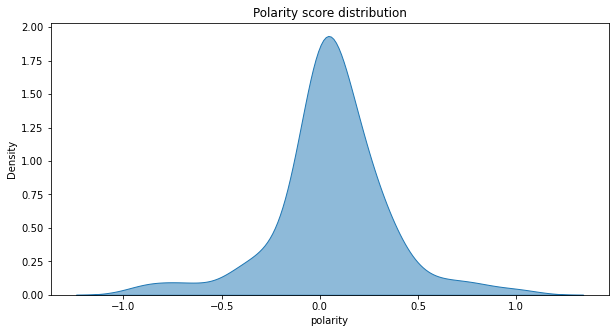
Description: The polarity score distribution graph shows a unimodal bell shaped distribution. A left skew is shown from the distribution which tells us that the mean gets pulled towards the tail, and is less than the median.
plt.figure(figsize=(10,5),facecolor='1')
plt.title('Subjectivity score distribution')
sns.kdeplot(
data=df, x="subjectivity",
fill=True, palette="Set1",
alpha=.5, linewidth=1)
plt.show()
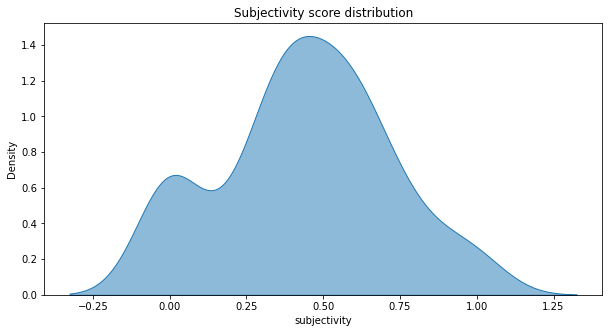
Description: The subjectivity score distribution graph shows a bimodal distribution. A slight right skew is shown from the distribution which tells us that the mean gets pulled towards the tail, and is greater than the median.
Label count
plt.figure(figsize=(10,5),facecolor='1')
plt.title('Count of polarity score')
sns.countplot(
data=df, x="polar_label",palette="Set1")
plt.show()
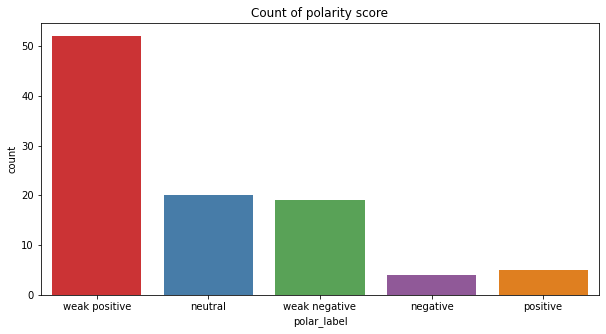
Description: The bar chart shows that count of polarity labels from the Fast 9 movie Reddit comments. From the chart we can see that most of the comments are ‘weak positive’. This shows that Reddit comments on the post are reacting slightly positive towards the movie.
plt.figure(figsize=(10,5),facecolor='1')
plt.title('Count of polarity score')
sns.countplot(
data=df, x="subj_label",palette="Set1")
plt.show()
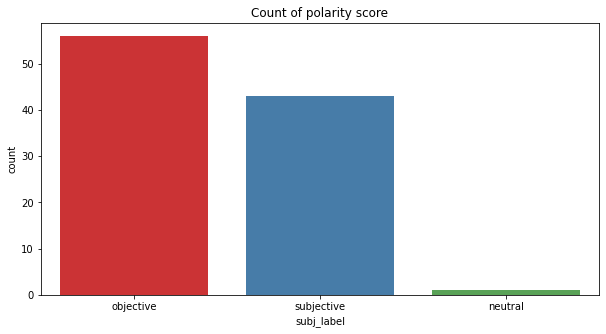
Description: The bar chart shows that count of subjectivity labels from the Fast 9 movie Reddit comments. From the chart we can see that most of the comments are ‘objective’. This means that most of the collected comments are mostly factual albeit by only a small margin.
Wordcloud
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# Text of all words in column Tweets
df_neg = df[df['polar_label']=='negative']
text = " ".join(review for review in df_neg.cleaned_comments.astype(str))
print ("There are {} words in the combination of all cells in column Tweets.".format(len(text)))
# Create stopword list:
# remove words that we want to exclude
stopwords = set(STOPWORDS)
# Generate a word cloud image
wordcloud = WordCloud(stopwords=stopwords, background_color="white", width=800, height=400,colormap='Set1').generate(text)
# Display the generated image:
# the matplotlib way:
fig=plt.figure(figsize=(10,5))
plt.tight_layout(pad=0)
plt.axis("off")
plt.imshow(wordcloud, interpolation='bilinear')
plt.show()
There are 328 words in the combination of all cells in column Tweets.

# Text of all words in column Tweets
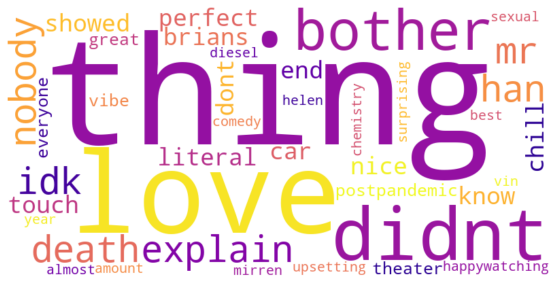
df_neg = df[df['polar_label']=='positive']
text = " ".join(review for review in df_neg.cleaned_comments.astype(str))
print ("There are {} words in the combination of all cells in column Tweets.".format(len(text)))
# Create stopword list:
# remove words that we want to exclude
stopwords = set(STOPWORDS)
# Generate a word cloud image
wordcloud = WordCloud(stopwords=stopwords, background_color="white", width=800, height=400,colormap='plasma').generate(text)
# Display the generated image:
# the matplotlib way:
fig=plt.figure(figsize=(10,5))
plt.tight_layout(pad=0)
plt.axis("off")
plt.imshow(wordcloud, interpolation='bilinear')
plt.show()
There are 274 words in the combination of all cells in column Tweets.